研究発表Publications
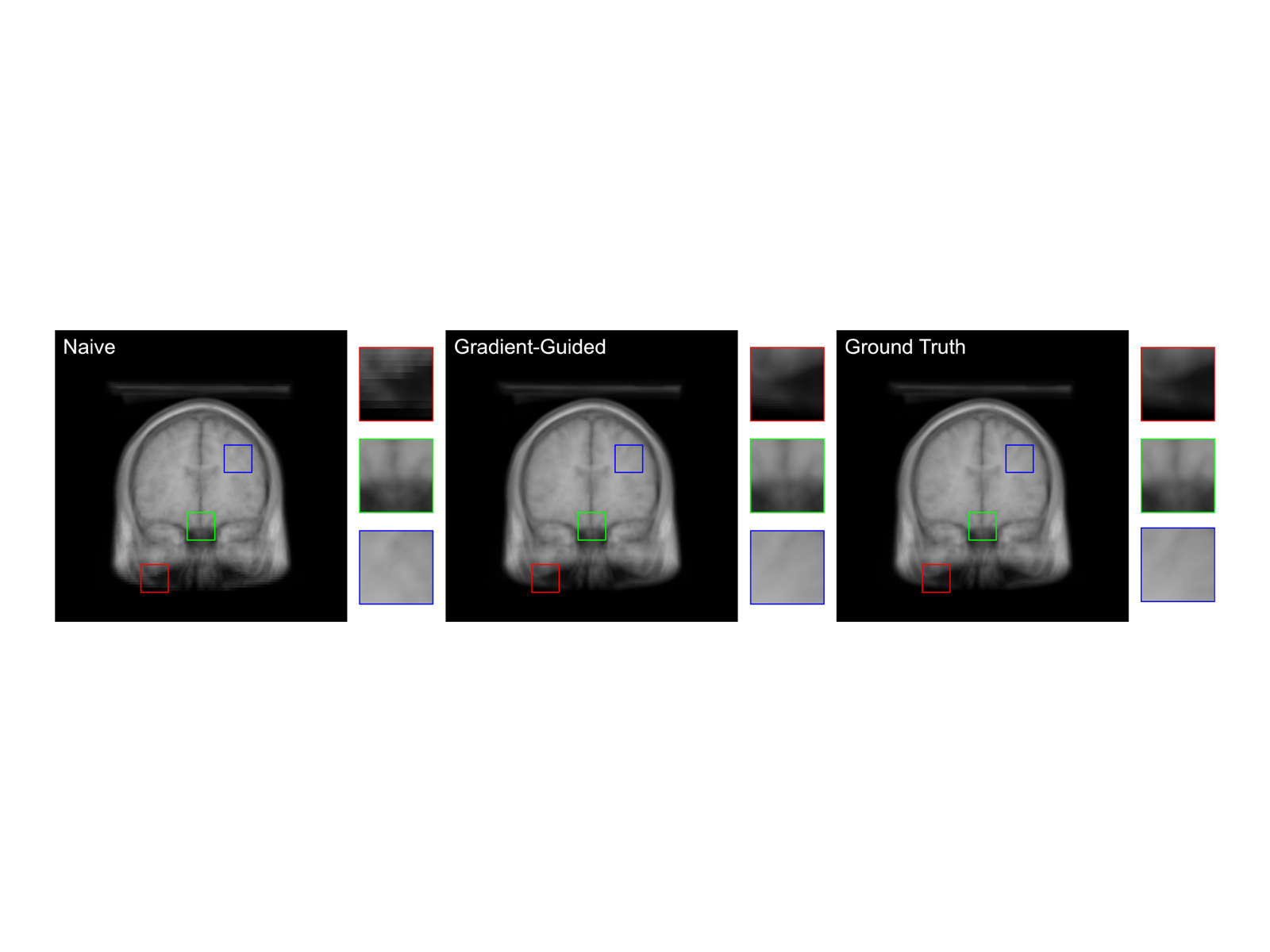
Gradient Traversal: Accelerating Real-Time Rendering of Unstructured Volumetric Data, Mehmet Oguz Derin, Takahiro Harada, In Proceedings of SIGGRAPH 2024
We present a novel gradient traversal algorithm for real-time volume rendering of large, unstructured, dense datasets. Our key contributions include a two-pass approach consisting of a gradient estimation pass with random offsetting and a divergent gradient traversal refinement pass, achieving significant improvements over traditional methods per traversal step. By leveraging modern GPU capabilities and maintaining uniform control flow, our method enables interactive exploration of complex, dynamic, unstructured volumetric data under real-time constraints, addressing a critical challenge in scientific visualization and medical imaging.
Download PDF
Compression and Interactive Visualization of Terabyte Scale Volumetric RGBA Data with Voxel-scale Details,Mehmet Oguz Derin, Takahiro Harada, Yusuke Takeda, Yasuhiro Iba, In Proceedings of SIGGRAPH 2022
We present a compressed volumetric data structure and traversal algorithm that interactively visualizes complete terabyte-scale scientific data. Previous methods rely on heavy approximation and do not provide individual sample-level representation when going beyond gigabytes. We develop an extensible pipeline that makes the data streamable on GPU using compact pointers and a compression algorithm based on wavelet transform. The resulting approach renders high-resolution captures under varying sampling characteristics in real-time.
Download PDF
Sparse Volume Rendering using Hardware Ray Tracing andBlock Walking, Mehmet Oguz Derin, Takahiro Harada, Yusuke Takeda, Yasuhiro Iba, In Proceedings of SIGGRAPH ASIA 2021
We propose a method to render sparse volumetric data using ray-tracing hardware efficiently. To realize this, we introduce a novel data structure, traversal algorithm, and density encoding that allows for an annotated BVH representation. In order to avoid API calls to ray tracing hardware which reduces the efficiency in the rendering, we propose the block walking for which we store information about adjacent nodes in each BVH node's corresponding field, taking advantage of the knowledge of the content layout. Doing so enables us to traverse the tree more efficiently without repeatedly accessing the spatial acceleration structure maintained by the driver. We demonstrate that our method achieves higher performance and scalability with little memory overhead, enabling interactive rendering of volumetric data.
Download PDF
Universal Dependencies for Old Turkish, Mehmet Oguz Derin and Takahiro Harada, In Proceedings of SyntaxFest 2021
We introduce the first treebank for Old Turkic script Old Turkish texts, consisting of 23 sentences from Orkhon corpus and transliterated texts such as poems, annotated according to the Universal Dependencies (UD) guidelines with universal part-of-speech tags and syntactic dependencies. Then, we propose a text processing pipeline for the script that makes the texts easier to encode, input and tokenize. Finally, we present our approach to tokenization and annotation from a crosslingual perspective by inspecting linguistic constructions compared to other languages.
Download PDF